
If you have a PDF of a book chapter or journal article, it’ll be one of two basic types.1
On the one hand, it might just be a series of page images. If this is what you have, you can click on it all you want, but all you’ll select is the whole page image.
On the other hand, your PDF might already have real text inside it. If so, you’ll be able to select specific letters or words inside the PDF. If do select, copy, and paste some of the PDF’s text, you might find some problems with the result (e.g., unnecessary line breaks that get retained). But that PDF is already a whole lot more usable than an image-only version.
Also, if you have real text inside a PDF, you’ll have other benefits too, including how the PDF’s text will be
- easier to mark up (e.g., with underlines, highlights) if you read it electronically,
- searchable, and
- accessible by screen or PDF audio readers, like Librera PDF ( F-Droid, Google Play).
If you have an image-only PDF, however, you’re not stuck without these benefits. You can use Tesseract to perform “optical character recognition” (OCR) on your PDF. As it does, Tesseract will
- “look” at an image-only PDF,
- give a best guess about what text is on the page, and
- save that text back with the image into another, combined PDF.
Tesseract’s OCR may not be perfect, but it has come a long way and is now quite good. And using it to add text to your image-only PDFs will definitely make them more usable.
0. Install Zotero.
Tesseract itself is a command-line tool. So, by itself, it doesn’t have a window or any buttons to click to make the program run. You’re left to type commands out.
This process can be helpful in some cases—if you want to run OCR on a large batch of PDFs at once, for example. But it’s probably pretty different from the way you’re used to interacting with your computer.
Fortunately, though, Tesseract integrates nicely with Zotero, the popular reference manager. Zotero has a “graphical user interface” (i.e., a window and clickable buttons).
You might find Zotero incredibly helpful in its primary capacity as a reference manager. But even if you don’t use Zotero in this way, it gives you an easy way to work with your image-only PDFs through Tesseract.
So, if you haven’t already, take a moment to download and install Zotero.
1. Get Zotero ready.
Once you have Zotero installed, you’ll need to prepare it to handle your image-only PDFs.
1.1. Install Tesseract and Poppler
To do so,
- download and install Tesseract OCR for Windows 2 or Linux or Mac and
- download and extract Poppler for Windows 3 or Linux or Mac into a directory where you’re okay with it staying (e.g.,
%userprofile%\AppData\Local\Poppler).
1.2. Install Zotero OCR
Once you have these tools, download the most recent version of the Zotero OCR extension (e.g., zotero-ocr-0.8.1.xpi). Then, with Zotero open,
- go to
Tools > Plugins, - click the gear button in the upper right-hand corner of the
Plugins Managerdialog box, and - choose to
Install Plugin From File….
In the Select add-on to install dialog box, navigate to the folder where you downloaded the Zotero OCR extension, click the extension file, and then click Open.
Zotero will then install the OCR extension. And after installing, you might need to close and reopen Zotero for the extension to function properly.
1.3. Configure Zotero OCR
After you reopen Zotero,
- Go to
Edit > Settings > Zotero OCR. - For the path to your
tesseract executable, enter the path totesseract.exe. On Windows, the path to this file will probably be something like%userprofile%\AppData\Local\Programs\Tesseract-OCResseract.exe. But you’ll need to enter your actual user profile folder path as the variable%userprofile%won’t get expanded and, consequently, won’t allow Tesseract to run. Your userprofile folder should be something likeC:\Users\YOURUSERNAMEONWINDOWS. If you’re unsure, however, you can go toStart > Command Prompt, and typeecho %userprofile%. You’ll then see what%userprofile%is equal to, including whatever folder representsYOURUSERNAMEONWINDOWS. - For the path to your
pdftoppm executable, enter the path topdftoppm.exe(e.g.,%userprofile%\AppData\Local\Poppler\Library\bin\pdftoppm.exe). Here again, on Windows, you’ll need to use not%userprofile%but whatever folder%userprofile%points to (e.g.,C:\Users\YOURUSERNAMEONWINDOWS). - Customize the other options according to your preferences. For instance, if you want Zotero OCR to
- recognize multiple languages in a PDF, you can add as many as you like in the
Choose a language/script you want to use for recognition (default is eng):field from the list of languages Tesseract recognizes. For instance, enteringeng+deu+fra+grc+heb+hye+latwill mean Tesseract tries to OCR text as English, German, French, Greek, Hebrew, Armenian, and Latin.4 - produce a PDF that has OCR text included, be sure you check the
Save output as a PDF with text layeroption. But you may want to leave un checked the option to overwrite the initial PDF, just in case something goes amiss.
- recognize multiple languages in a PDF, you can add as many as you like in the
- Once you’re done customizing your preferences for Zotero OCR, click the close button on the
Zotero Settingsdialog box.
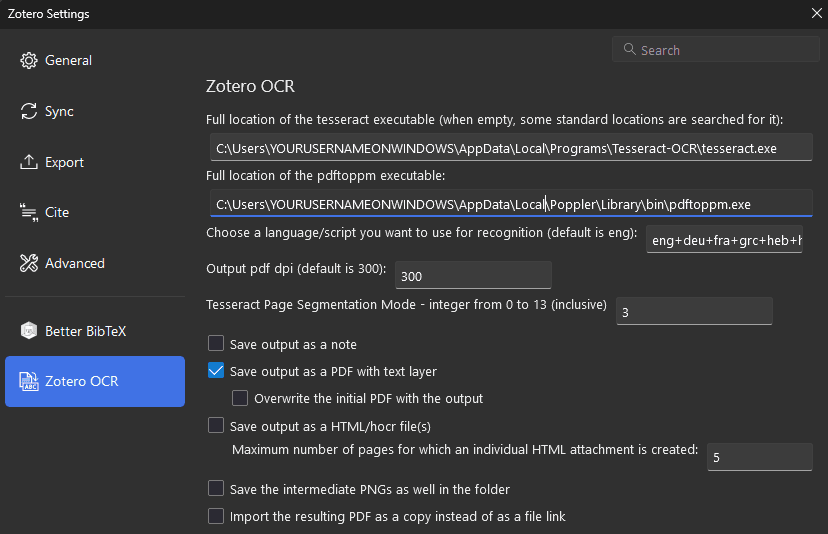
Image illustrating the Zotero Settings dialog box when configured as described in this section’s instructions
2. Create a PDF with real text.
At this point, Zotero is ready to
- run OCR on any image-only PDF in your library and
- create a new PDF that renders your original PDF’s page images with real text.
To do so, find an image-only PDF in Zotero. If you don’t have any, drag-and-drop one from anywhere on your computer onto the My Library header in the left-hand panel.
Then, right click this PDF, and choose to OCR selected PDF(s). After you click this option, you’ll want to be patient. The process may take a while, even with a comparatively short PDF. And it can look like not much is happening.
But eventually, you should get a command line window that gives you some progress indicators as Tesseract works through your PDF. If you never get this window, double check that tesseract.exe and pdftoppm.exe are actually where you told Zotero OCR to find them.
When Tesseract finishes, you’ll see a new linked attachment in Zotero with a .ocr.pdf ending to the file name. You can use this file to interact with the real text that Tesseract worked out for your PDF’s page images. Zotero’s indexer and your PDF reader’s find function can do the same as well.
If you want to be able to search the across your PDFs in Zotero, you might want to rebuild or update your Zotero index ( Edit > Settings > Advanced > Search > Rebuild Index…).
3. Clean up the leftovers.
If you don’t care to keep the leftovers from the conversion process, you can clean them up at this stage. Just right-click either the new linked file attachment or the original one in your Zotero library, and choose to Show File.
You’ll then be shown the Zotero storage folder where your PDFs are stored. You can now open and try using the text that Tesseract added in the .ocr.pdf file.
And if you’re satisfied with the results of the conversion, you can delete your original PDF from this folder and rename the .ocr.pdf file to omit the .ocr portion of its file name. It should then have the same name as your original PDF.
Be sure not to touch the .zotero-ft-cache or .zotero-ft-info files. But any leftover .txt files you can also delete. Or if you find that your new PDF’s OCR text leaves some things to be desired, you can easily correct the text you find in the .txt file and retain that text alongside your new PDF.
If you do rename .ocr.pdf to .pdf and you had Zotero OCR add a linked attachment to the file it created, that attachment will now be available through the original stored file link in Zotero (the one without the little chain icon). So, you can delete also the Zotero link to the .ocr.pdf file (i.e., the one with the little chain icon), since you’ve now renamed that file.
Conclusion
Having real text in a PDF makes that document much more usable. It’s easier to mark up electronically, it’s searchable, and it’s accessible by screen or PDF audio readers.
Older PDFs or PDFs of older sources might not come with this real text already in them, and OCR is rarely perfect. But you can use Zotero to add a good amount of accurate text to your image-only PDFs, which will make annotating, referencing, and using these files much easier.
-
Header image provided by Zotero via Twitter. ↩︎
-
On the download page, find the line
The latest installers can be downloaded here:, download the indicated EXE file, and install the program as usual. ↩︎ -
On the download page, download the most recent
Release-*.zipfile (e.g.,Release-24.08.0-0.zip), and unzip the download by right clicking the file and choosing toExtract All…. ↩︎ -
On the other hand, maybe you aren’t going to need multilingual OCR support and, perhaps, don’t want to use Zotero. If so, the Freedom of the Press Foundation’s Dangerzone may be a simpler way to perform single-language OCR on your image-only PDFs. ↩︎